6 Generative AI Fundamentals
It is useful to learn some fundamental aspects about GenAI models prior to intergrating them into your workflows. I have often found that there are many guides online that tell you how to use these models, but don’t tell you why you should do what they’re telling you to do. Although the guidance given by these guides is often useful, when you don’t get the output you want it doesn’t give you the skills to critically think about what might have gone wrong.
Even though generative AI models continue to demonstrate functional improvements without extensive prompt engineering, having some foundational knowledge of how these models work will serve you well in building your own generative AI workflows.
6.1 What is Generative AI?
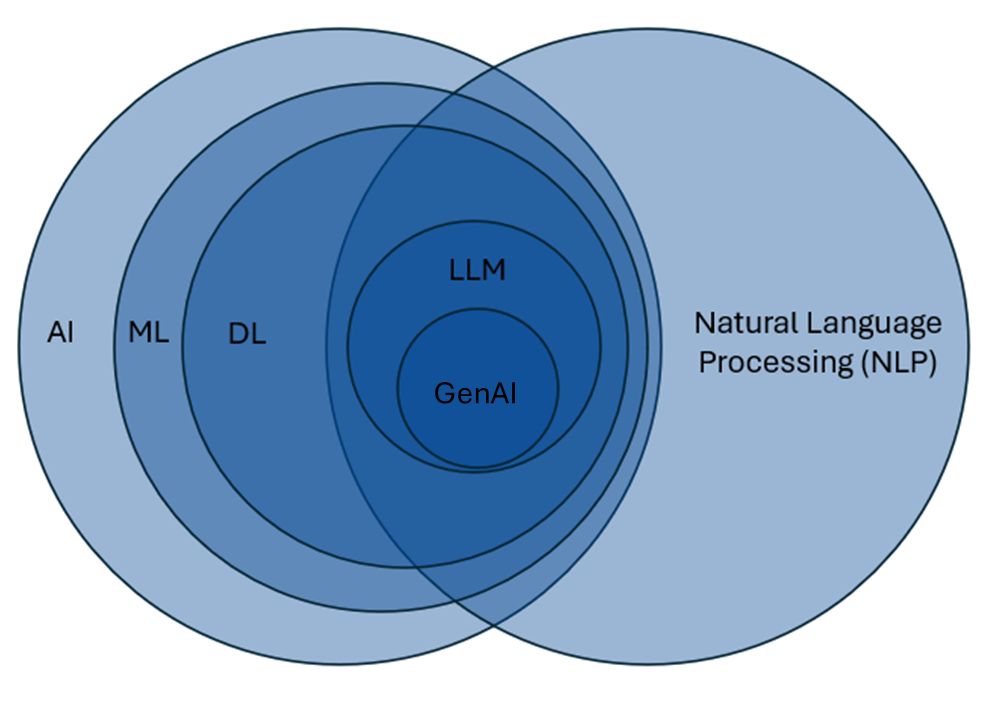
So what is generative artificial intelligence? We often hear the words GPT, generative AI, AI, LLM, and machine learning models used somewhat interchangeably and that isn’t always necessarily the case. Sometimes the speaker may not understand that they’re referring to something they don’t intend to refer to, or sometimes the technical aspects of what exactly they’re referring to doesn’t quite matter.
In this diagram, I’ve attempted to show you the relationship between Artificial Intelligence, Natural Language Processing, and many related fields, with Generative Artificial Intelligence in the middle. The scale of the circles in this image is not accurate – I’ve only attempted to show the relationships these fields.
Working from the left-hand side inward, our outermost circle is Artificial Intelligence, or AI. Artificial intelligence is the broad field of computer science focused on creating systems that can perform tasks typically requiring human intelligence, such as problem-solving, reasoning, and understanding language. I’ve heard some people argue that statistical models like regressions can be included in this large circle because you’re learning about relationships in data that are not directly observable. I’m not sure that I’m convinced of this argument, but it does give you an idea of how broad the field of AI can be construed.
As we start to go inward, we next have Machine Learning. Machine learning is a subset of AI that involves using algorithms that learn patterns from data and improve their performance on tasks over time without being explicitly programmed for every possible scenario; the models usually have some type of predictor variable selection method, drawing from a large set of options in the data.
This is different from a regression, where you identify all the key predictor variables of interest based on your knowledge of the domain. With machine learning you just need to identify enough of the potentially relevant variables to maximize your predictions. Here is where we start to encounter so-called “black box” models because sometimes interpreting the decision-making processes of the algorithm becomes difficult due to the complex nature of the models. One common example is when the values of some predictor variables are take on exponential functional forms - how do we easily interpret this, especially if there are complex interactions?
Going further inward, we have Deep Learning, which is a subset of Machine Learning models. These models eliminate the need for identifying variables due to the large amount and variety of data that are supplied to the models. Deep Learning models use very complex algorithms to identify complex patterns in the data, and their results are often more uninterpretable. These algorithms are usually unsupervised, in the sense that even outcome variables aren’t specified in the models - instead you’re more interested in the complex relationships that exist between all of the data together. This is good for things like speech and natural language, where relationships between variables are not easily identified.
I’ll now jump to the right-hand side and the large field of Natural Language Processing. Broadly speaking, natural language processing is focused on enabling computers to understand and interpret human language. There are areas of NLP that don’t overlap with machine learning or deep learning, such as sentiment analysis or topic modeling, both of which may not use Machine Learning or Deep Learning Models.
If we look at the overlap between deep learning models and natural language processing models, we see that Large Language Models (LLMs) live here. LLMs represent a deep learning approach within NLP that leverages vast amounts of text data to generate and understand human-like language. These models go beyond traditional NLP techniques by using statistical learning to predict and produce coherent, context-aware text at scale. Not all LLMs are generative AI models, such as some of the different transformer models.
Now, finally, in the middle we have Generative AI Models (Gen AI). These models that are a specific type of LLM that are designed to generate output that model resemble their training data. The most common model is a generative text model, although models are now being developed that have the capability to generate images, audio, and video.
6.2 What is a Generative Pre-trained Transformer?
Generative Pre-trained Transformers (GPTs) are a type of generative AI model. While not all generative text models have “GPT” in their name, understanding their underlying structure can be helpful for learning how these models work. Let’s look at each letter in the acronym:
6.2.1 Generative
The G in GPT stands for generative, which refers to the model’s ability to generate new content based on its training data. This is similar to having a very large dataset and running a regression. Based on the results, you have a good idea of the relationship of the predictor variables and the outcome. Once you have this data, you can then make predictions on new cases that share the same predictor variables. If the new case is well-represented in your data, then your predictions will usually be fairly accurate. However, if the new case is less-well represented in your data, then you will likely have to extrapolate your data to make the best guess you can, usually with large standard errors.
This (extrapolating beyond your training data) is one way that generative AI models may hallucinate, or produce an error in their response (either factual or structural). While we’re talking about training data…
6.2.2 Pre-trained
Generative AI models undergo a vast amount of model pre-training (P). In a generative text model, this includes a vast corpus of text data. To give you an idea of how large this training data is, when I was first learning about these models, I often heard presenters say some of these models were trained on all the publicly-available text on the internet. Having such a vast amount of data equips the model with a broad “understanding” of language and its nuances. This understanding is a recognition of the patterns of word usage across many contexts.
It is important to note that the models are made to generate content and do not have the ability to reflect on the factual accuracy of the information that is provided. If the training data contains extensive information that is related to the input, there’s a higher probability that it will be correct, but there is no guarantee. When using text models, these models are merely predicting the most likely next token in the output. There is no self-reflective step where the model evaluates whether the information being provided is factually accurate.
6.2.3 Transformer
And, finally, T – transformer. This refers to the specific neural network architecture that makes models like GPT so powerful. Before transformers were introduced, models processed language sequentially, one word at a time, which limited their ability to capture long-range context, understand ambiguities (e.g., pronoun referents, ambiguous negation, etc.), or parallelize computations efficiently. The transformer architecture revolutionized this process by allowing models to “pay attention” to all parts of a text at once. Attention helps the model determine which words (or tokens) are most relevant to predicting the next one (we’ll talk more about attention soon.
This design has two major advantages: it scales extremely well to large amounts of data, and it captures meaning flexibly across varying contexts. In other words, the transformer gives modern language models both their power and fluidity.
This blog post on Financial Times is a great visual explanation of transformers (and related concepts) transformers without being too technical.